The Context
So recently I was trying to interact with an avi file with a video stream encoded in H.264 and an audio stream encoded in MP3. To my surprise, my trusty Perian 1.1 failed to even play the video and gave me a black screen (though the audio played just fine). With some Google-fu, it was found in a forum post that the SVN version of Perian fixed this error.
So compile my own Perian 1.1.1b1 from SVN, right? No big deal. Heh. And thus begins our story. (Note that this procedure is accurate as of the time of writing. OSS projects change rapidly as bugfixes are checked in. You may not have this problem at all. But it’s still useful as a reference in the future, in case similar problems arise).
Problem 1: AVCodecContext.bits_per_sample
The first problem you hit is probably:
/tmp/perian-orig/ff_private.c:181: error: ‘struct AVCodecContext’ has no member named ‘bits_per_sample’
…
/tmp/perian-orig/FFissionCodec/FFissionDecoder.cpp:289: error: ‘struct AVCodecContext’ has no member named ‘bits_per_sample’
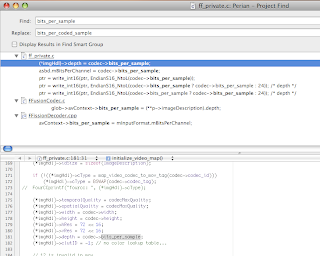
Turns out that the upstream project FFMPEG, who is responsible for libavcodec, has very recently changed the API in one of its latest revisions. bits_per_sample has become
bits_per_coded_sample in revision 15262. Because Perian’s SVN does an external SVN checkout of the HEAD of libavcodec, it pulled these API-breaking changes without considering whether that breaks its own compilation or not.
The fix is simple enough: global search and replace the member variable to bits_per_coded_sample.
Problem 2: Xcode’s unnatural fondness for dynamic libraries
At this point, libavcodec compiles, so you think you’re home free. For most users, that is probably the case. For some of us, though, there’s one more hurdle.
While compiling Perian.component, you might get something like:
ld warning: in /Developer/SDKs/MacOSX10.4u.sdk/usr/local/lib/libavcodec.dylib, file is not of required architecture
Undefined symbols:
"_avcodec_close", referenced from:
…and so on
Closer examination reveals that at some point, you might have compiled FFMPEG or MPlayer or any of the many media projects that depend on FFMPEG libraries (for me, that was transcode, whose own compilation idiosyncracies I documented in an earlier post). When you installed these libraries, they went into your library search path. Note the Perian compilation line immediately preceding the compile failure:
/Developer/usr/bin/g++ ... -read_only_relocs suppress -lavcodec -lavformat -lavutil -lebml -lmatroska ... /tmp/perian/UniversalDetector/build/Release/libuniversaldetector.a -lbz2 -o /tmp/perian/build/Deployment/Perian.component/Contents/MacOS/Perian
 As you can see, the -lavcodec linker argument will cause the linker go on the search path and try to find the library. It of course first finds your pre-installed library in /usr/local/lib or some other system lib path, and tries to use it. If you compiled that library as Intel only or PPC only and you tried to build a universal Perian, that would obvious fail and generate an architecture error. If you, like me, compiled only for x86_64 or ppc64, that would also trigger the same architecture problem (as Perian builds as x86 32-bit).
As you can see, the -lavcodec linker argument will cause the linker go on the search path and try to find the library. It of course first finds your pre-installed library in /usr/local/lib or some other system lib path, and tries to use it. If you compiled that library as Intel only or PPC only and you tried to build a universal Perian, that would obvious fail and generate an architecture error. If you, like me, compiled only for x86_64 or ppc64, that would also trigger the same architecture problem (as Perian builds as x86 32-bit).
This problem stumped a user “vs”, in this Perian-discuss Google groups thread. Notice how the devs didn’t get the root of the problem, and answered snarkily and defensively to the user bug report.
The devs aren’t wrong, though. Didn’t we just see a statically compiled target, libavcodec.a, in the target list for the Perian Xcode project? Why yes, yes we did! In fact, there are static targets for all of the -lav* libraries in the Xcode project. So why did the linker go off and use -lavcodec rather than, say, $PERIAN_DIR/build/Universal/libavcodec.a, as instructed?
The workaround
In short: Xcode is screwing things up. Xcode 3.1 has a distinct (some say, unnatural) preference for dynamic libraries. When you add a library to the “Link Binary With Library” listing under Targets, it simply adds a -l<libname> to the link line to pass to ld at link time. When this happens, it will look for lib<libname>.dylib (in this case, libavcodec.dylib, libavformat.dylib, libavutil.dylib, etc in your library path. If it finds one, it will use that one rather than the static library you provided in the Xcode project file. Obviously, this ends up linking the wrong library, perhaps with the wrong architecture or the wrong version. Compilation explodes.
The workarounds are not very clean. There seems to be no good way to instruct Xcode to forget its dynamic library fetish and use the static versions you provide. You could remove the dylibs from the system library path entirely — when the linker fails to find the .dylib version, it will fall back to the .a.
Alternatively, you can explicitly instruct it to use static linking as an environment flag and remove the built-in Xcode linker relationships:
- Right-click on your Target (in this case, Perian) and Get Info to bring up the Target Info box.
- Go to the Build tab
- Select your Build configuration – in this case, probably Deployment
- Find or locate OTHER_LD_FLAGS, also called “Other Linker Flags”
- Manually add the paths to the .a files in this field, one at a time. If you don’t know the path, right-click -> Get Info on the desired libraries under Link Binary With Library, and it should show you a field called Full Path on the General tab. That’s the path to use. Should look something like /tmp/perian/build/Universal/libavcodec.a
- Do the same for all offending libraries – this may include libavcodec, libavformat, libavutil, libmatroska, etc.
- Remove the libraries you added to Other Linker Flags from your Xcode’s Target -> Target Name -> Link Binary With Library section, to stop Xcode from auto-generating broken linker flags. This is important.
If done correctly, this should no longer find the wrong type of the library. Your compilation of Perian should proceed as normal.
The Moral of the Story
Xcode has some weird idiosyncratic ways of building its projects. It’s useful to poke at things and find out about these behaviors. Its unnatural preference for dynamic libraries over your explicit instructions is disturbing, though.
Don’t attack your users when they pose a problem, and drop the attitude of: ooo, we’re doing this for free, so fsck off, users. In both problems, the exact same attitude surfaced amongst a few of the devs. Arrogance (“we don’t have the responsibility to do anything for you”) and snarky dismissal (‘Well, there’s your problem. We don’t build libavcodec.dylib nor do we place it in /usr/local/lib.’) helps no one. No matter what you thought your build script did, the linker is heading off toward /usr/local/lib, and you better damn well find out why.
It’s obvious that there’s something peculiar going on with the link process, and the user tried to make it clear multiple times (“You missed my point. We build a .a file and we don’t put it in /usr/local/lib.”), but no one seems to pay attention. Following that thread, the user is increasingly frustrated and expresses that, and now the dev’s hammer of arrogance comes down hard ( “You looked like a prick here, to be honest.” — really? not your obtuse-ness or your blindness to a user need?)
When you have a “works-for-me” situation, it’s especially important to communicate effectively with the user. In most cases, you have no idea why it blows up for the user and not for you. Admitting it is fine — could be a very localized issue for that user, or could reveal a subtle systemic problem in your code – either way, it’s useful to have that established. I realize we’re all very busy people, but at the end of the day it’s still your project. Either acknowledge you have no idea what’s going on and solicit help and cooperation with the user who’s having this issue, or man up, put on your detective hat, and fix your own damn problems. The rest of us are busy with our own issues.
The Free Software culture seems to breed this sort of contempt for the user in some devs. Might be a paper in analyzing how corrosive this can be.
UPDATED: I certainly do not mean this last section as a criticism for all Free Software devs. The vast majority of people I’ve talked to in the various communities are really knowledgeable, helpful folks. There are just a few people in some cases, though, who seem to think that if the user can’t make the software work, it’s somehow the user’s fault. It’s a joint problem to be solved together, not “you’re an idiot if you can’t make it work”.
UPDATED 2 (9-29-2008): Perian 1.1.1 has been released. This should fix the original problem with H.264 and .avi files that prompted this post.