If you have a series 8 NVidia graphics card (say, an 8600M GT) with current drivers (as of the time of this post, of course), you’re likely to see graphics glitches (screenshot 1) in Baldur’s Gate 1. One workaround is to use 16-bit color and software transparent BLT. Another strategy, if your CPU is powerful enough to shoulder some 2D graphics work, is to temporarily turn off hardware acceleration for DirectDraw and avoid the bug entirely. 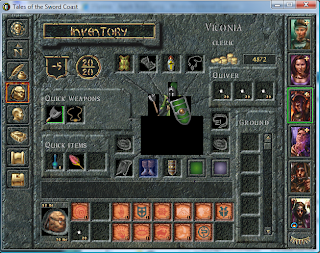
However, disabling hardware acceleration under Vista is apparently easier said than done. Instead of using the Personalization -> Display Settings control panel (as one might think to do based on Windows XP experience), the correct solution is to use the DirectX SDK and dxcpl.exe, the DirectX Control Panel (located within the SDK distribution under Utilities\bin\[cpu_arch]\. From within this control panel, pick DirectDraw on the upper tab bar. Amongst the various configuration options available on that tab, the only one you care about is the box to turn on or turn off hardware acceleration. Turn that off (temporarily, of course) and you’re good to go.
The Context
Baldur’s Gate 1 performs surprisingly well under Windows Vista, despite being a venerable (some might say, ‘ancient’) 10-year old RPG. Unfortunately it’s plagued by a number of graphics glitches when running on NVidia cards. In essence, a number of items and sprites (items on the belt, the timepiece to the lower left corner, birds flying overhead, for example) will be surrounded by black outlines. Further, on your character paper doll in the Inventory screen, giant black boxes obscure much of the figure. In some cases, the ‘fog of war’ on the unexplored regions of a map will be rectangular black boxes, rather than the ‘foggy’ darkness you’re used to. These glitches are widely experienced.
For this very annoying problem, two workarounds are available.
1. Trade color depth for correctness
The prevalent strategy, as noted in a forum post at Spellhold Studios, is to switch on Software Transparent BLT and use 16-bit color depth. This apparently routes around whatever strange bug NVidia managed to introduce in their graphics acceleration layer.
This method works just fine, but was not ideal for me. The game runs at 640 x 480, and is already quite pixelated when scaled up to full screen. 16-bit vs 32-bit color is somewhat noticeable, once at that scale.
2. Trade performance for correctness
Here’s another classic trade-off. Since the problem is obviously arising from the DirectX layer and its interaction with NVidia graphics hardware (boot into safe mode and run BG1 to verify this), another solution is to just kick NVidia out of the loop by disabling hardware acceleration for DirectDraw. This is feasible if you’re doing this on a fast machine (and if you’re using a series-8 card in that box, I’d assume it’s pretty fast anyway) – after all, BG1 is a 10-year old game. Your Core 2 Duo or quad-core Xeon can use some exercise anyway.
Of Hardware Acceleration Controls
In the glory days of XP, this simply meant right-click on Desktop -> Properties -> Settings -> Advanced -> Troubleshoot -> Hardware Acceleration slider (dear god that’s convoluted). In Vista, the analogous experience is right-click on Desktop -> Personalize -> Display Settings -> Advanced Settings -> Troubleshoot -> Change Settings (I see you still haven’t hired a good user experience designer, Microsoft).
The problem now is that if you try this with your NVidia card and Vista, you’ll just be staring at a disabled ‘Change Settings’ button and a terse message: 'Your current display driver does not allow changes to be made to hardware acceleration settings.' If you also try the old standby dxdiag, you might be surprised to know that the Disable buttons have been removed from the DirectX Features box on the Display tab. Thanks, NVidia and Microsoft. Apparently they really don’t want us changing these settings.
But we don’t really want to change much – just the DirectX technologies, and in fact, just the 2D-based DirectDraw (since 3D is more or less irrelevant for BG1), and only for a short while. Enter the DirectX SDK.
The SDK is meant for developing and debugging DirectX-based programs, but it comes with a fair suite of nifty utilities, one of which being the DirectX Control Panel: dxcpl.exe. Download the 400+ MB SDK (this is the 2008 version of the SDK — you might look for a newer version if you’re on Win 7; I think the control panel still ships with the latest versions) and grab the control panel in Utilities\bin (starting from where you installed the SDK to). Make sure that if you are on x64 (x86_64) that you also use the x86 architecture control panel for BG1, as it seems to be required to affect 32-bit mode apps (see comments for this post for more details).
In the control panel, use the DirectDraw tab – in the set of checkboxes, uncheck the “Use Hardware Acceleration” box. Fire up BG1 and see the non-black-boxed goodness of 1998 graphics (screenshot 2).
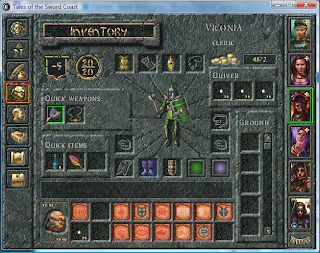
If you were disabling acceleration for another reason, this control panel should work for you too – pick the appropriate tab and have at it. Do not forget to turn acceleration back on after the session. You probably do not want unaccelerated graphics performance in your normal, non-glitchy apps.
Turning off hardware accelerated DirectDraw avoids the BG1 black-box bug. You’ll have to assess for yourself which is more expendable: color depth (trivial to change directly from BG1’s Options configuration) or graphics performance (more difficult to tweak, but perhaps compensated by CPU performance).
DirectX SDK vs Settings slider
In any case, the DirectX control panel is a somewhat useful trick to know in general, especially when faced with Vista’s obstinate insistence on not letting you change graphics acceleration settings. The control panel provides all the functionality that the old XP Settings slider would have give you – except in a much more technical interface. In fact, the old slider more or less tweaked settings in the Direct3D and DirectDraw tabs, except in a coarse-grained, all-or-nothing kind of way. Here at least you have fine-grained control on most of the detailed options in each panel.
Still, such a pain.
Know that tweaking these settings are done at your own risk (NVidia and MS obviously are against it), and may or may not work at all depending on your setup, your driver version, and pure luck. On the plus side, if you ever need to write some DirectX apps, the SDK is now just a few clicks and SDK path text fields away from Visual Studio 2005/2008, so the 400 MB bandwidth and disk space isn’t completely wasted. Hopefully.
UPDATE 9/8/2008
It’s come to my attention that some people still have problems after applying this fix – namely, there are cursor trails on menu screens. I cannot reproduce this issue locally on my 8600M GT, but it’s possible that there are new problems introduced with newer series-8 cards and drivers. If this is the case, I’d recommend using the first workaround — that is, using Software BLT and 16-bit color, rather than the DirectDraw workaround.
UPDATE 7/15/2009
There is now a Nvidia driver .dll patcher available for BG1-era Infinity Engine games at Spellhold Studios. They also explain what the underlying issue is and what the DLL wrapper does to work around the bug. I have not personally tested this fix. It does install a new graphics DLL that overrides existing calls, so it is theoretically possible that it may introduce other issues, but I am told by others that it works quite well. Check it out — it saves you a lot of trouble of ticking DirectDraw boxes on and off, if you don’t mind unofficial DLL patching.
UPDATE 2015
There are still people arriving at this page, 7 years later after the initial post. At this point, you should probably just buy the remastered Baldur’s Gate Enhanced Edition on Steam instead. Much, much less hassle.




